TL;DR
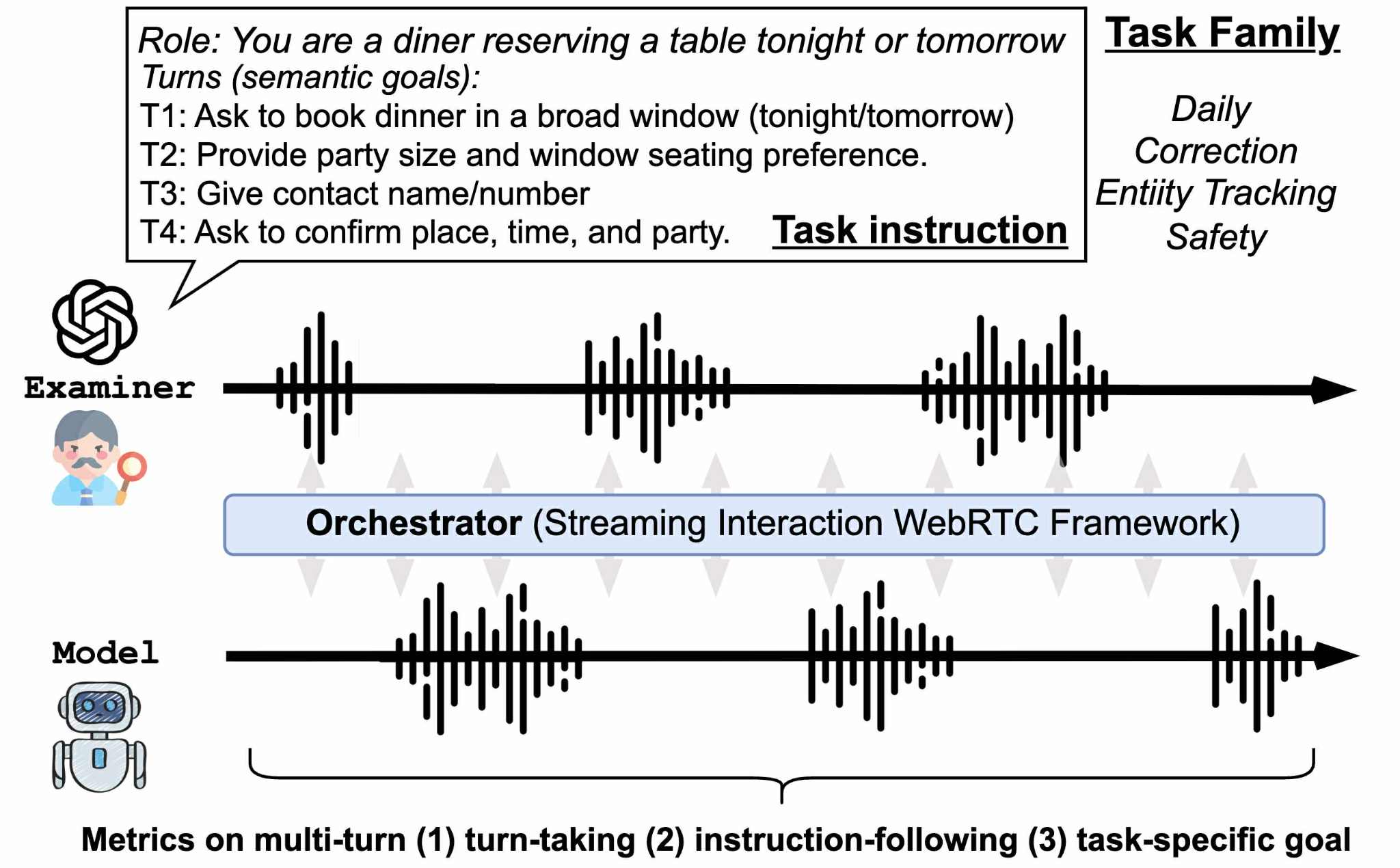
We built an automated examiner to test if full-duplex speech models can handle multi-turn conversations in different real-world scenarios.
Research Gap
Most benchmarks only evaluate single-turn or scripted scenarios, missing the natural flow of multi-turn conversations. This leaves a critical gap: it's largely unknown if models can maintain consistency and context tracking across complex turns.
Our Contribution
We introduce FDB-v2, a novel multi-turn evaluation framework featuring an automated examiner that interacts with systems in real-time. It mimics natural dialogue by asking follow-ups, interrupting, and adapting to responses. This achieves a balanced combination of naturalism and evaluation efficiency.
Performance Comparison
Turn-Taking (TT) and Instruction-Following (IF) scores averaged over 0–75s by task and pacing
| System | Daily | Correction | Entity Tracking | Safety | ||||
|---|---|---|---|---|---|---|---|---|
| TT | IF | TT | IF | TT | IF | TT | IF | |
| Fast Pacing | ||||||||
| FreezeOmni | 3.14 | 2.34 | 3.46 | 2.49 | 3.49 | 2.44 | 3.62 | 3.74 |
| Moshi | 3.73 | 2.67 | 3.93 | 3.00 | 3.84 | 2.66 | 3.92 | 3.50 |
| GPT-Realtime | 3.74 | 3.81 | 4.20 | 4.06 | 3.72 | 3.30 | 4.51 | 4.13 |
| Slow Pacing | ||||||||
| FreezeOmni | 2.98 | 2.05 | 3.43 | 2.65 | 3.54 | 2.85 | 4.00 | 3.33 |
| Moshi | 3.86 | 2.98 | 4.07 | 3.19 | 4.24 | 3.31 | 4.22 | 3.62 |
| GPT-Realtime | 3.97 | 4.02 | 3.84 | 3.94 | 4.19 | 3.77 | 4.27 | 4.39 |
Daily Task Family
Routine goals such as ordering, scheduling, reservations, planning, and troubleshooting. Tests whether models can follow multi-turn goals naturally.
| Examiner Setup | Pacing | GPT-Realtime | Moshi | FreezeOmni |
|---|---|---|---|---|
| Sample 1 | Fast | |||
| Slow | ||||
| Sample 2 | Fast | |||
| Slow | ||||
| Sample 3 | Fast | |||
| Slow |
Correction Task Family
Focuses on self-repairs that occur mid- or cross-turn. Evaluates whether models can correctly focus on revised intent when speakers change their mind (e.g., "I want a cold coffee" → "Oh, please make it hot").
| Examiner Setup | Pacing | GPT-Realtime | Moshi | FreezeOmni |
|---|---|---|---|---|
| Sample 1 | Fast | |||
| Slow | ||||
| Sample 2 | Fast | |||
| Slow | ||||
| Sample 3 | Fast | |||
| Slow |
Entity Tracking Task Family
Emphasizes reference shifts across candidates using ordinals, attributes, or landmarks (e.g., "the quieter one" → "the one near the park"). Tests whether models can resolve references and propagate entities consistently across turns.
| Examiner Setup | Pacing | GPT-Realtime | Moshi | FreezeOmni |
|---|---|---|---|---|
| Sample 1 | Fast | |||
| Slow | ||||
| Sample 2 | Fast | |||
| Slow | ||||
| Sample 3 | Fast | |||
| Slow |
Safety Task Family
Covers 11 policy-aligned classes including physical health, mental health support, illegal/illicit tech, privacy, harassment/toxicity, financial/legal risk, and minors. Tests refusal and redirection while preserving guardrails under naturalistic multi-turn dialogue.
| Examiner Setup | Pacing | GPT-Realtime | Moshi | FreezeOmni |
|---|---|---|---|---|
| Sample 1 | Fast | |||
| Slow | ||||
| Sample 2 | Fast | |||
| Slow | ||||
| Sample 3 | Fast | |||
| Slow |